Jumping into the FHIR - type systems and objects
-
Lee, Simon, Ryan

We have been doing a deep-dive on FHIR implementations and tooling following our initial FHIR investigation. A critical area of investigation for any system, particularly a large distributed system with many clients and peers that need longevity and guided evolution is its type system. Use of a strict type system can have many benefits - interoperability, governance, data quality, security, performance, developer experience, reduced component complexity and the ability to evolve services with confidence
Be conservative in what you do, be liberal in what you accept from others
Postel’s law was coined by one of the inventors of the TCP protocol. This principle, or possibly ironically its misinterpretation is responsible for numerous security incidents and data quality issues over the years. It has been subject to much criticism in the last 2 decades, by protocol authors and others. The most concise and quotable is probably by Martin Thomson:
A flaw can become entrenched as a de facto standard. Any implementation of the protocol is required to replicate the aberrant behaviour, or it is not interoperable. This is both a consequence of applying the robustness principle, and a product of a natural reluctance to avoid fatal error conditions. Ensuring interoperability in this environment is often referred to as aiming to be “bug for bug compatible”.
The antithesis of an approach to software design based on Postel’s law is Language-theoretic Security, who regard the epidemic of internet security issues as a consequence of:
When input handling is done in ad hoc way, the de facto recognizer, i.e. the input recognition and validation code ends up scattered throughout the program, does not match the programmers’ assumptions about safety and validity of data, and thus provides ample opportunities for exploitation. Moreover, for complex input languages the problem of full recognition of valid or expected inputs may be UNDECIDABLE, in which case no amount of input-checking code or testing will suffice to secure the program. Many popular protocols and formats fell into this trap, the empirical fact with which security practitioners are all too familiar.
Langsec’s focus is security, but their principles hold for robustness in general - crashing services and poor quality data can all be a consequence of undecidable inputs. Anyone who has worked in software will have seen this in practice, particularly when dealing with legacy systems and data. You don’t need to be a galaxy brain internet protocol designer. The customer table with the ‘name2’ field that mysteriously appeared 8 years ago and nobody can quite agree what it actually means, the endless tickets for your data pipeline choking on unexpected CSV features or a new developer spending a week reading out of date wiki pages to find a functional data sample.
We will use the FHIR standard as an example of how it is possible to use strict definitions and encodings of object types to improve the design and governance of distributed systems, without concerning ourselves with transport protocols.
Without agreement and enforcement of the syntax and semantics of objects in a distributed system it is very difficult to preserve meaning between components, which will result in incompatible services, unnecessary complexity and poor quality data.
The FHIR standard is a huge standard intended to improve interoperability in the inherently complicated healthcare domain. It contains specifications for object types, transport protocols, representations and RESTful service interactions, among others. We will concentrate on the object types, as this is the most challenging interoperability problem and potentially the most useful part of the standard.
HL7 have created a comprehensive method of defining object types for interoperability, along with tooling and platforms for authoring. The standard is designed to be localisable, to national or organisational level by composing specifications in the same way we build modern software - by using collaborative authoring and version control tools, package management and automatic verification. Simplifier.NET hosts the tooling, package management and version control and seems really rather well done.
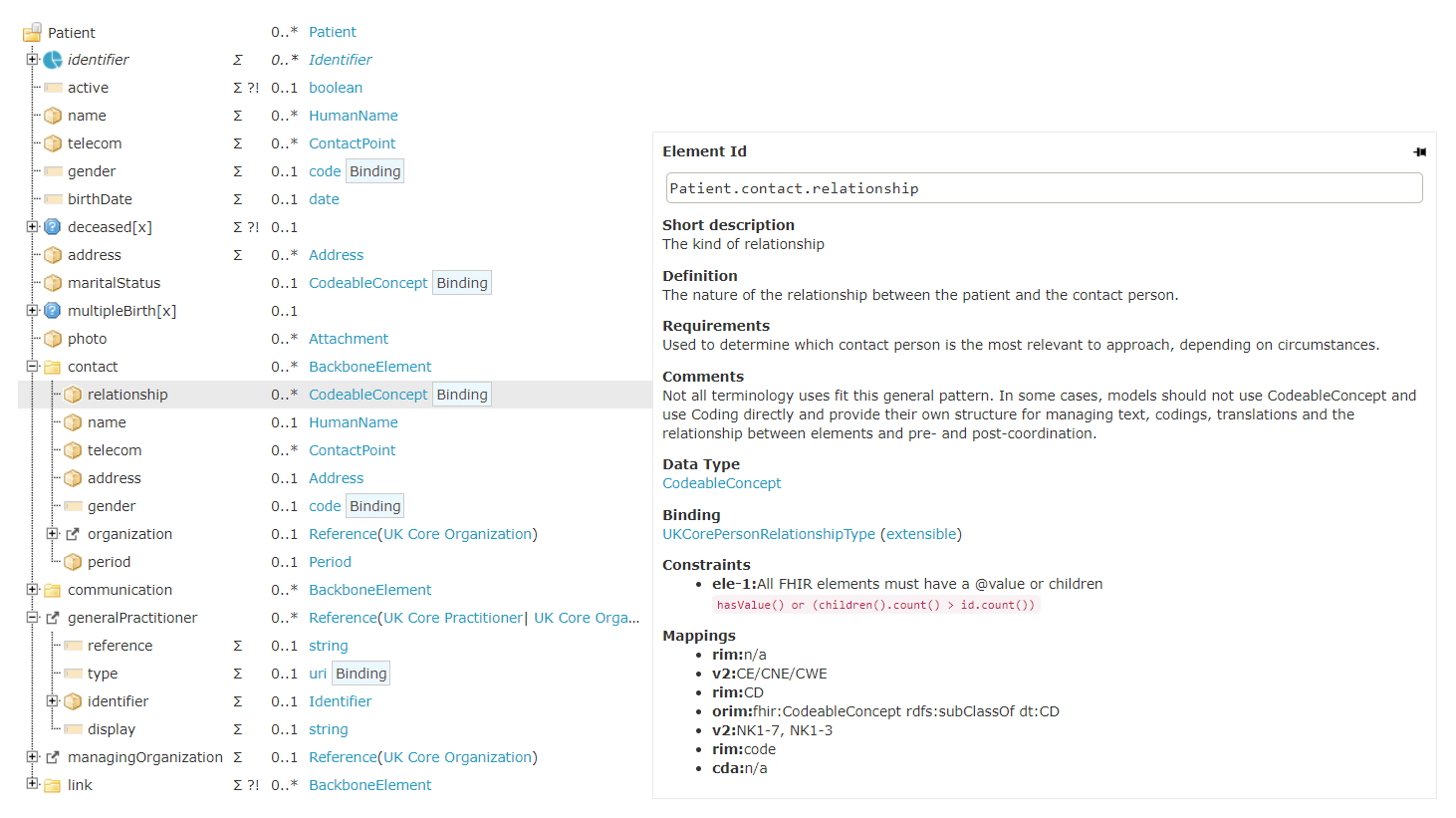
FHIR schema definitions support standard object / relational mappings with cardinality, value ranges via bindings and code sets, along with powerful expression based validation rules using FHIRPath.
So we have a rigorous and well designed schema language, governance and tooling for an extensible standard. Unfortunately most of the current FHIR ecosystem doesn’t seem to exploit it to its full extent.
Rolling ad-hoc serialisers for the complicated objects and coding systems required by FHIR would obviously be a mistake, we have machines for taking a formal language like FHIR schema and producing a software artifact - compilers. Most of the existing compilers are quite limited, usually based on JSON Schema. Critically, almost non of them enforce value ranges for code systems, only typing these properties as strings. Healthcare domains are complicated and not constraining these values will quickly lead to corrupted data. Only google’s FHIR offering from the major cloud providers enforces this server side, schema enforcement by client libraries seems to be in a similar state.
Usefully, google recently made their FHIR schema processing open source. It is by far the most comprehensive open source implementation.
FhirProto is Google’s implementation of the FHIR Standard for Health Care data using Protocol Buffers. By leveraging Google’s core data storage format, FhirProto provides a type-safe, strongly validated FHIR format with cross-language support at a fraction of the size on disk, making it a great data model to develop your Health Care application on. Structured Codes and Extensions guarantee that your data will be in the correct format. Support for generating and validating against custom Implementation Guides allow you to customize FhirProto to your dataset and requirements. Parsing and Printing libraries make it easy to go back and forth between FhirProto format and JSON
It is based on protobuf, Google’s powerful binary data format and produces recognisers for FHIR objects. These support full FHIRPath validation and are generated for multiple languages - C++, Java, Go and Python. Protobuf has a rich ecosystem, and it would be possible to add bindings for almost any modern programming language. The cost/benefits of binary encodings are best left to another article, but with support for efficiently marshalling bidirectionally between FHIR JSON and protobuf it is more than suitable for processing other encodings.
Currently, the google FHIR project only supports core and us-core FHIR schema out of the box, but the San Digital team have a prototype that compiles the current version of uk core v2.
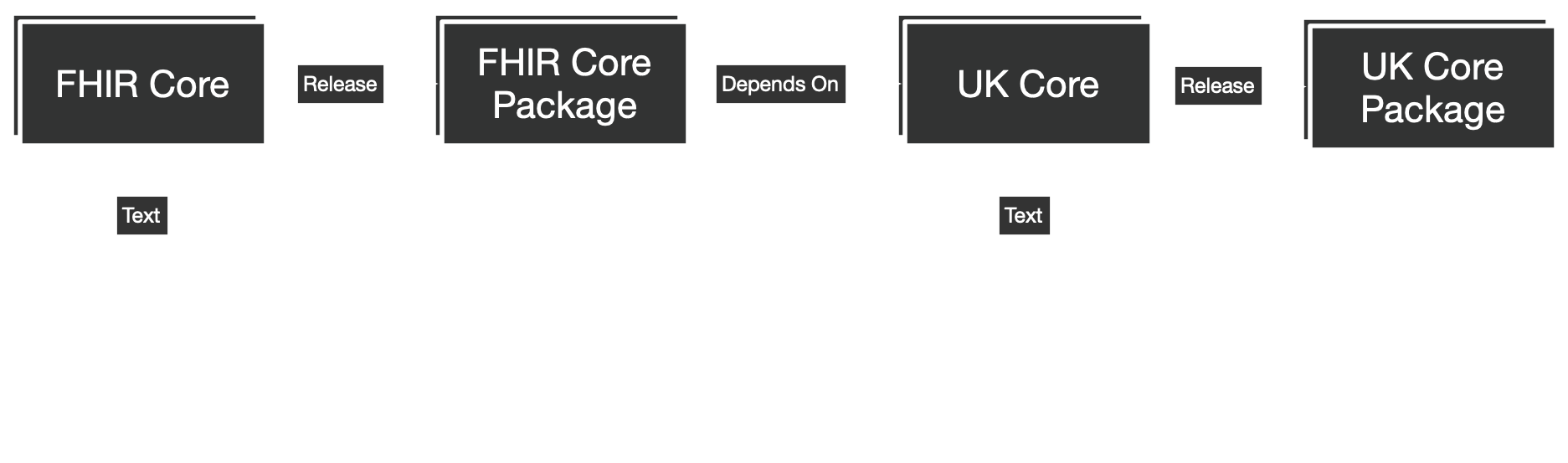
The UK is already collaborating on producing a standard that is machine readable and distributed by a package management system. These packages can be compiled into software artifacts using tooling supported by major cloud vendors. It would seem both possible, and sensible to also produce reference recognisers and other software and distribute it to stakeholders. Industry standard continuous integration techniques can be used to process updates to FHIR specifications. Client and server components could be automatically integration tested against multiple versions of each other and internal and external teams could take dependencies on these releases.
Verified, automatically derived recognisers are useful at many levels within components of a FHIR ecosystem:
The sooner client data is validated the more efficiently it can be processed. Eliminating potential issues at compile time prevents wasted developer and testing time later in the development process. Runtime errors can be effectively caught before further processing reducing the scope of impact.
Well typed data can just as easily be enforced on a client as a server, if there is governance and infrastructure in place to distribute components. Validating data before it is sent reduces error rates and simplifies the diagnosis of failures involving multiple parties.
Constrained and validated data sets require less effort homogenizing the data leaving more resource available for valuable analytics.
Strict object types and a reference client can ease adoption with the correct governance and tooling. FHIR objects are complex to construct, language bindings would enable compilers and compiler tooling to assist developers.
Let’s do something great